Architectural Notes
- Why are things the way they are?
- The Cluster View
- Global Clock
- Playbooks
- Scheduling Node Actions
- Platforms and discovery
- Cluster discovery
- Cluster orchestration
- Handling data models
- Distributed Coordination
- Scaling
- Releasing
Premature Optimisations
- Should it be better?
- Concurrent Agent Fetches
- Dynamic Config
- Rewrite Kafka Consumer
- Online Kafka stream resize
- Layered Configuration
- Lock validation before writes
- Multi-cache backend
- Stream Batches
- Rewrite Zookeeper Elections
- Path-based Apply API handlers
Dreamland
- What could the future bring?
- Auditing System
- Best practices checklists
- Cluster Groups
- Cluster Tags
- Replicante Core bootstrapping procedure
- Failure triggers detection
- Generic backends interface
- Metrics based insight
- Multi-Cluster Playbooks
- Multiple agent transports
- Node events collection
- Playbook Variables
- Provisioning integrations
- Rate Limits
- Read only mode
- Replication window metrics and re-sync times
- Resyncable WebUI application
- Secrets manager integrations
- TLS certificate rotation
Cluster orchestration
At the essence of Replicante Core is a state events engine: when a state change is detected actions are taken to adapt or to return the system to a desired state.
The idea of orchestration built on events is not new:
- It is an easy model to understand for humans (physics is based on the action-reaction paradigm).
- It is easy enough to implement (at least compared to other options).
- It allows us to focus on the triggers of an event and the consequences of an action without having to look at the entire history of the full system.
Additionally tracking state changes can tell us what is happening to our system and what we need to change as well as what our actions on the system lead to.
The cluster orchestration process continuously evaluates the state of clusters so decisions can be taken, progress tracked and (re)actions triggered.
So how does cluster orchestration work?
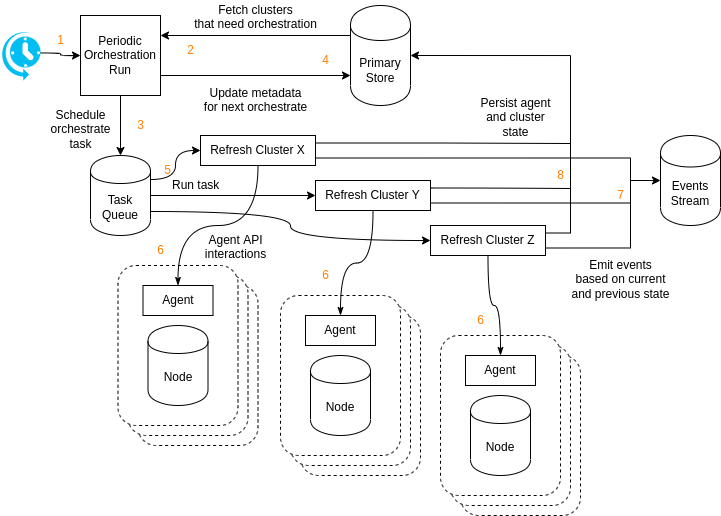
- The cluster
orchestratecomponent periodically runs at fixed intervals. The interval should be short as it determines the delay between cluster needing orchestration and the orchestration being scheduled. - The
orchestraterun looks for any cluster with an expected next orchestration time in the past. If no cluster needs to be orchestrated theorchestraterun does nothing. - The
orchestraterun schedules an orchestrate task for each cluster that needs to run. - The expected next orchestration time is updated to
now() + orchestrate interval. - A task worker picks up the orchestration task.
- The orchestration task performs all orchestration logic (see below).
- Events are emitted for state changes.
- The new cluster state records and aggregated generated data is persisted to the primary store.
Avoid concurrent orchestration tasks
Because events are generated from differences in observed states, orchestrating the state of a node from multiple processes at once may lead to duplicate and/or missing events as well as inconsistent aggregations.
Distributed locks are used to ensure a cluster is orchestrated by only one task at a time. Any cluster orchestration attempted while another operation is already running will be discarded.
Cluster orchestration logic
The above covers how Replicante Core manages orchestration tasks. This section covers how an orchestration task works against an individual cluster.
Logic overview
The orchestration logic performs the following steps sequentially:
- Build a cluster view (see below) from existing data about the cluster.
- Process each node in the latest cluster discovery record:
- Fetch updated information from the cluster nodes.
- Use this information to create an incremental updated view.
- Use this information and the starting cluster view to emit events.
- The information is saved to the primary store once relevant events are emitted.
- Schedule node actions not already scheduled.
- Progress and/or start any orchestrator actions waiting to be scheduled. Scheduling priorities and running actions are taken into account to determine which orchestrator actions can start.
- Perform data aggregation to report on the cluster as a whole:
- Report on cluster level metadata such as number of nodes, versions, etc …
A cluster view
The newly fetched cluster information is used to generate an approximate cluster view. This new cluster view is compared to a view based on the last known cluster data to generate events describing changes observed happening to the cluster.
Because the cluster view is approximate node events are always based on reporting from the node themselves (we do not report a node as down if we see it up, even if another node in the cluster think it is down).
Only cluster level events are generated off the top of this views. Actions will also have to check if the state of the cluster matches expectations before they are executed.