Architectural Notes
- Why are things the way they are?
- The Cluster View
- Global Clock
- Playbooks
- Scheduling Node Actions
- Platforms and discovery
- Cluster discovery
- Cluster orchestration
- Handling data models
- Distributed Coordination
- Scaling
- Releasing
Premature Optimisations
- Should it be better?
- Concurrent Agent Fetches
- Dynamic Config
- Rewrite Kafka Consumer
- Online Kafka stream resize
- Layered Configuration
- Lock validation before writes
- Multi-cache backend
- Stream Batches
- Rewrite Zookeeper Elections
- Path-based Apply API handlers
Dreamland
- What could the future bring?
- Auditing System
- Best practices checklists
- Cluster Groups
- Cluster Tags
- Replicante Core bootstrapping procedure
- Failure triggers detection
- Generic backends interface
- Metrics based insight
- Multi-Cluster Playbooks
- Multiple agent transports
- Node events collection
- Playbook Variables
- Provisioning integrations
- Rate Limits
- Read only mode
- Replication window metrics and re-sync times
- Resyncable WebUI application
- Secrets manager integrations
- TLS certificate rotation
Scheduling Node Actions
Playbooks are not a thing yet
They will provide a way to automatically schedule actions to perform orchestrated higher-lever operations across an entire cluster. Writing about the actions system assuming playbook are already here makes the entire system (agents and core) easier to think about and design.
Aspects related to Playbooks and how they work are likely to change significantly.
Each agent can run a single action at any time and has a queue of actions waiting to be executed. These actions can be scheduled either directly though the agent API or through Replicante Core. Replicante Core can schedule actions on behalf of a user or automatically as part of a playbook.
Generally, an agent’s actions queue should be short. Replicante Core will not generate new actions (even from playbook) until necessary and manually scheduled actions are expected to be few.
Nodes Actions scheduling
To minimise the complexity around actions concurrency Replicante Core pushes and pulls actions to and from Agents only during a cluster orchestration.
This may cause actions to stay in PENDING_SCHEDULE for a while as a sync needs to push
them down and one after that needs to confirm they where indeed pushed to the agent.
This delay on the other hand pays for simplicity, especially when scheduling needs to be retired.
As a result, the process of scheduling action in Replicante Core works as follows:
- An action is recorded in Replicante Core with a
PENDING_*state. - The action is left untouched until it reaches the
PENDING_SCHEDULEstate. - During a cluster orchestrate operation, for each node:
- Core fetches actions updates from the agent.
- Any
PENDING_SCHEDULEaction in Core is scheduled on the agent. - Errors are captured for debugging but ignored to avoid blocking orchestrating of other nodes in the cluster.
Retries are automatically performed at the next cluster orchestration.
Actions are processed by creation time by both agents and Core. This provides a simple way to ensure actions execute fairly without a “late comer” taking the spotlight. This is of course not a fool proof method: time skew as well as scheduling actions directly with agents instead of Core are examples of why actions may execute “out of order”.
The only rule or ordering, enforced by each agent, is that actions execute sequentially and no new action is started until the currently running action is complete.
During the cluster orchestration process actions may not actually be scheduled. Replicante Core uses the cluster view and recently fetched node information to choose:
- Actions are not scheduled if the node is not healthy (
Status::Up). - Based on actions concurrency and scheduling policies documented in the Core user guide.
Conflicting actions
Node actions can be scheduled directly with Agents setting an action ID for them. This is required so that Replicante Core can generate IDs for Actions without having to interact with any Agent.
This opens the system to the situation where Replicante Core and an Agent may have different actions with the same ID.
If this ever happens the Agent wins and Replicante Core will overwrite its Action record with the data received from the Agent during the next cluster orchestration.
Actions and playbook progression
Actions progress when the agent reports that their state has changed.
Actions progress from an initial state (like NEW) to a finished state like (DONE or FAILED).
Playbooks progress when all actions in the current stage have finished. Playbooks progress in a similar way to actions, moving along stages.
Both actions and playbooks progress checks are reactive: events have to trigger them. This is opposed to active checks where the system would have to poll pending and running actions and playbooks and check if they can progress.
Reactive checks are more efficient because resources are not spent checking over and over for states that have not changed. Reactive checks also make Replicante Core far simpler to implement.
Events that cause actions and playbook progression are emitted by the cluster orchestration
tasks when agent actions change state or when pending actions exist.
To ensure users have an escape hatch in case the system fails to auto-detect
progress the API will allow scheduling a cluster task to nudge actions and playbooks.
Action States
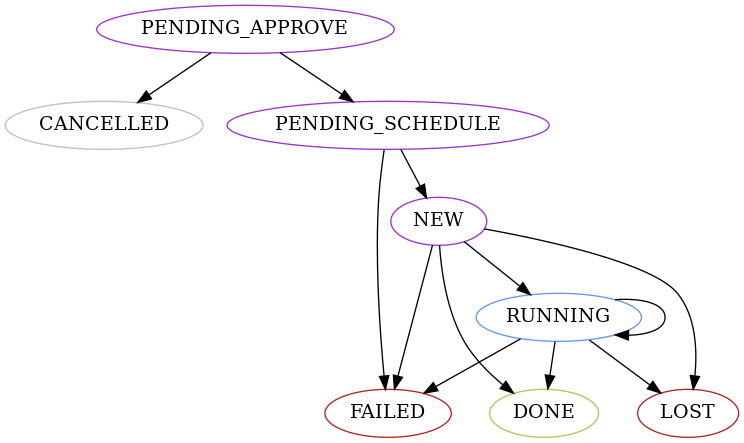
State colour legend
- Black : intermediate Core state.
- Blue : intermediate Agent state.
- Green : successful outcome state.
- Gray : action did not execute final state.
- Red : unsuccessful outcome state.
- Violet : starting state.
States descriptions
CANCELLED
The action was interrupted or never executed.
DONE
The action finished successfully.
FAILED
Unable to successfully execute the action.
LOST
Agent records of an action were purged before Core synced them.
NEW
The Replicante Agent knows about the action and will execute it when possible.
PENDING_APPROVE
Replicante Core knows about the action but can’t schedule it until it is approved. These actions can be approved through the API so they can be scheduled.
PENDING_SCHEDULE
Replicante Core knows about the action and may or may not have sent it to the Agent.
RUNNING
The action is running on the Replicante Agent.